
Simplification Of Adult Intelligence Assessment Reports With ChatGPT: An Exploratory Case Study
Aim and Research Question(s)
This thesis aimed to compare psychologist-written intelligence assessment reports (WAIS) with ChatGPT-simplified versions of the same reports, by assessing if the ChatGPT reports were:
- Easier to read for nonpsychologists?
- Easier to understand for nonpsychologists?
- Maintained in terms of quality from a psychology perspective?
Background
ChatGPT’s popularity highlights how accessible Artificial Intelligence (AI) has become. Unsurprisingly, this development in popularity poses difficult and interesting questions about where the area of AI is going. For example, if we can really trust this technology with important matters such as healthcare. Healthcare reports, such as the Wechsler Adult Intelligence Scale (WAIS), have the ability to inform and improve patient care, safety, and legal aspects [1]. Large language models (LLMs), such as ChatGPT, have started to be used to simplify text for patient reports, but it remains unknown how accurately they perform [2]. WAIS reports also lack established report writing guidelines, which often leads to great variety in the report's readability, understandability, and quality.
Methods
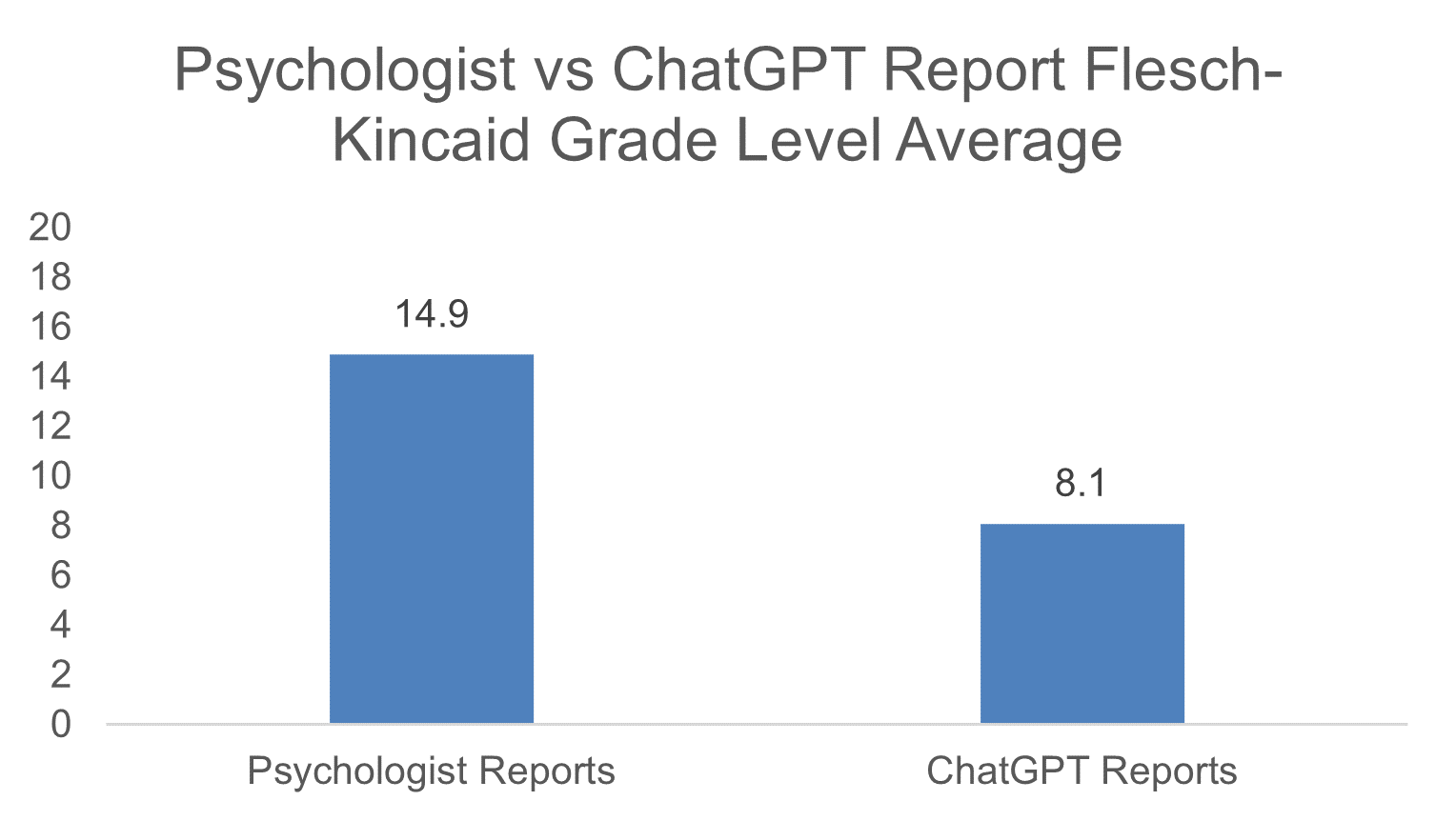
To investigate, an exploratory case study focusing on a comparison between psychologist-written WAIS reports and ChatGPT-simplified versions of the same reports was conducted. First, the Flesch-Kincaid Grade Level test was used to assess and compare readability levels [3]. Second, an adapted version of the Patient Education Material Assessment Tool (PEMAT) was used to assess and compare understandability [4]. Third, a psychologist-informed checklist was developed to assess the quality of the reports.
Results and Discussion
The ChatGPT-simplified reports were found to be significantly easier to read, yet not significantly more understandable. However, they were rated “understandable” on the PEMAT, whereas the psychologist-written reports were rated “poorly understandable”. The psychologist-written reports were found to be significantly higher in quality. Psychologists noted the potential to use ChatGPT's reports for specific cases (e.g., cognitive impairment), which highlights the potential role for ChatGPT as an augmentation tool in the report writing process.
Conclusion
While further studies are needed, the initial insights of this study indicate a great potential in using LLMs, like ChatGPT, to improve patient-centered care through text simplification of WAIS reports. It may be that a tool such as ChatGPT is suitable for augmenting the role of a psychologist when writing a report for select target audiences.
References
[1] Lapum, J. et al. (2020). Reasons for documentation. Documentation in Nursing 1st Canadian edition. [2] Jeblick et al (2022). ChatGPT Makes Medicine Easy to Swallow: An Exploratory Case Study on Simplified Radiology Reports.[3] Flesch, R. (1948). A new readability yardstick. The Journal of applied psychology, 32(3), 221–233. [4]Shoemaker et al. (2014). Development of the Patient Education Materials Assessment Tool (PEMAT): a new measure of understandability and actionability for print and audiovisual patient information. Patient education and counseling, 96(3), 395-403.